
Rendre exploitables les données de mortalité de l’Insee
Temps de lecture : 11 minute(s)

Remerciements
Je tiens à remercier chaleureusement Pierre, de la chaine Décoder l’Éco, pour ses précieux conseils. Statisticien et analyste, c’est un fin connaisseur des méthodes statistiques utilisées par l’Insee, et c’est à lui que nous devons l’idée de la création d’une liste fine, tenant, quotidiennement, le compte des décès, mais aussi le vivier restant à cet âge dans la population, ce qui permet de calculer au jour le jour le taux de mortalité par âge, ou tranche d’âge. C’est lui aussi qui m’a fourni les clés afin de recréer une pyramide des âges tenant compte des décès dans l’année mais aussi des mouvements naturels (immigration notamment), et c’est lui encore qui m’a expliqué quels codes « départements » devaient être exclus pour ne retenir que les données concernant la France métropolitaine. Sans lui, ce projet n’aurait pas vu le jour.
Introduction
Plus qu’un article, il s’agit d’un projet assez vaste, aujourd’hui abouti, celui de rendre facilement exploitables les données de remontées de l’Insee, et de les mettre en parallèle avec les données concernant la démographie (pyramides des âges). Ces fichiers, ou plutôt les squelettes et les scripts nécessaires à leur reconstruction et à leur maintien sont désormais à disposition des chercheurs ou simplement des citoyens qui souhaiteraient réaliser leur propres analyses.
Le problème est que ces données brutes, publiées par l’Insee (à contrecoeur, c’est une obligation de la CADA) sont lourdement entachées d’erreurs et truffées de doublons. Il convient donc de les nettoyer des scories qu’elles contiennent, et cette opération n’est pas triviale.
Et pour que l’ensemble des données résultantes aient la moindre validité scientifique/statistique, il convient de ne rien effacer, de ne rien modifier, mais seulement de marquer d’un code d’erreur les fiches que nous écarterons au moment de créer les listes affinées. Et dans le souci de la transparence, les processus de marquage doivent être parfaitement décrits et formalisés, afin que chacun puisse s’assurer de la validité des marquages, par classe d’erreur.
Cette formalisation dans des scripts et des requêtes évite aussi les erreurs humaines inhérentes aux manipulations manuelles répétitives de données dans divers logiciels pas toujours adaptés comme Excel. On parle ici de 26 millions de lignes, la limite dans excel est à 1.048.576.
Exploitabilité des fichiers depuis 1970
Pour faire court, il faut oublier ça tout de suite, sauf pour analyser des tendances grossières. Les fichiers commencent à être exploitables à partir de 2000, et sont pratiquement parfaits (une fois nettoyés) à partir de 2012. Si votre but est de réaliser des analyses fines, il vaut mieux ne pas remonter au dela du 01.01.2012.
Les classes d’erreurs, et leur prévalence
| Nbre | Description | Code |
|---|---|---|
| 78 | Décès survenu avant la naissance | 1 |
| 12 | Date Décès incomplète | 2 |
| 552 | Date naissance 0000 00 00 ou incomplete | 3 |
| 75268 | Date naissance xxxx 00 xx | 4 |
| 17893 | Date naissance xxxx xx 00 | 5 |
| 241 | Date Décès xxxx 00 xx | 7 |
| 410 | Date Décès xxxx xx 00 | 8 |
| 10860 | Lieu Décès vide | 9 |
| 11 | Lieu Naissance vide | 10 |
| 30783 | Acte deces vide | 11 |
| 206402 | Double (nomprenom, sexe, danaiss, lieunaiss, datedeces, lieudeces) | 100 |
| 11501 | Double (nomprenom, sexe, datenaiss, lieunaiss[2], datedeces, lieudeces[2]) | 101 |
| 18225 | Double (sexe, datenaiss, lieunaiss, datedeces, lieudeces, actedeces) | 102 |
| 22599 | Double (sexe, datenaiss, lieunaiss, datedeces, lieudeces) | 103 |
| 1192 | Double (nomprenom, sexe, datenaiss, lieunaiss, datedeces) | 104 |
Comme vous le voyez, pour les seuls doublons, on en trouve 259.919 soit presque 1% du total des lignes présentes dans les fichiers.
Les erreurs sont marquées dans un certain ordre. Les erreurs qu’on peut gérer, comme une date de naissance partiellement incomplète seront marquées avant le code 3 qui concerne des gens dont on n’a pas la moindre idée de leur date de naissance. C’est gênant parce que quand vous calculez leur âge, c’est le même que le petit Jésus.
De même, pour les classes de doublons (Ercode ≥ 100), ceux-ci sont marqués en commençant par les critères les plus lâches pour terminer avec la classe 100. En clair, cela veut dire que si deux fiches sont identique pour les champs (nomprenom, sexe, datenaiss, lieunaiss, datedeces) ET qu’elles sont aussi identiques pour (nomprenom, sexe, danaiss, lieunaiss, datedeces, lieudeces), c’est le code 100 qui écrasera le code 104.
Les catégories que nous allons exclure sont : 1, 2, 3, 6, 7, 8, 9, 100, 101, 102, 103, 104
ErCode 9 : lieu de décès vide
Vous me direz, pourquoi exclure des gens dont on ignore juste la commune de décès? La réponse courte à cette question est… Parce que l’Insee le fait aussi ! Cela on peut le voir clairement sur le graphique que j’ai produit aux fins de validation du modèle par comparaison au séries longues de l’Insee. La réponse longue est sans doute plus gênante pour l’Insee. On imagine mal que l’Insee puisse avoir reçu des remontées de mairies… Sans savoir sur quelle commune le décès était survenu. Des citoyens s’en étaient d’ailleurs offusqués sur le forum du Ministère. Pourquoi l’Insee a-t-elle effacé ces codes pour ces 10.860 personnes? Mystère, ils s’en sont peut-être servi comme variable d’ajustement pour faire cadrer la mortalité avec les tableaux démographiques. J’ai posé la question sur le forum, sans réponse pour l’instant…
Les listes intermédiaires
Un des objectifs premiers du projet est d’arriver à la création de la liste appelée InseeFine. Dans cette liste, on tient, par jour, par département, par âge, le nombre de décès survenus, et le solde restant après avoir déduit ces décès à partir du solde au jour précédent. Ainsi, pour chaque jour, vous pouvez déduire, pour un âge donné, le taux de mortalité quotidien exprimé par la formule décès/solde*1000 pour l’avoir en ‰.
On comprend que pour créer cette liste, nous devrons le faire jour par jour, en tenant à jour le solde dans chaque tranche d’âge, cela ne peut se faire en une seule requête et nécessite un bout de programme rédigé en langage impératif. Pour la simplicité et afin de garder l’ensemble au même endroit, j’ai écrit ce programme dans une procédure stockée en MySql intitulée CreateListeFine.
Mais avant ça, il y a du pain sur la planche, notamment les filtrages, le calcul des âges et les regroupements des décès à un âge donné, pour tel jour, dans tel département.
Table InseeShort
Dans un premier temps, nous allons filtrer, pour écarter les lignes en erreur, et calculer l’âge des gens. Une fois de plus, cela a l’air simple, mais cela pose des difficultés parfois surprenantes.
Pour les fiches ayant des dates de naissance complètes, on peut facilement calculer l’âge révolu. Pour les fiches ayant des dates incomplètes, on doit y aller « à l’arrache » avec la formule suivante :
Floor((substring(Datedeces,1,4)*365.25+Substring(Datedeces,5,2)*30.5+Substring(Datedeces,7,2)- substring(Datenaiss,1,4)*365.25+Substring(Datenaiss,5,2)*30.5+Substring(Datenaiss,7,2))/365.25)
Et alors qu’on se croyait sorti des ronces, on trouve une fiche d’une personne née le 29.02.1913, ça ne s’invente pas. Et pour celui-là on relance la moulinette de la formule à l’arrache.
Le filtrage se fait :
- Sur les codes d’erreur : 1, 2, 3, 6, 7, 8, 9, 100, 101, 102, 103, 104
- Et les « départements » : 00, 96, 97, 98, 99
Et on ne retient que les champs qui nous seront ultérieurement utiles, ce qui donne quelque chose comme ça :
| id | sexe | datenaiss | datedeces | lieudeces | src | ercode | age |
|---|---|---|---|---|---|---|---|
| 14516742 | 2 | 19050417 | 20000118 | 95572 | 2000 | 0 | 94 |
| 14532422 | 2 | 19060723 | 20000101 | 03185 | 2000 | 0 | 93 |
| 14532423 | 1 | 19111228 | 20000102 | 03185 | 2000 | 0 | 88 |
Table InseeResume
Cette table regroupera les décès survenus pour un jour donné, dans le même département, au même âge, par sexe, et ajoutera également un champ DOW (day of week).
| dt | dow | biss | age | sexe | dep | deces |
|---|---|---|---|---|---|---|
| 2000-01-01 | 7 | 0 | 52 | 1 | 01 | 6 |
| 2000-01-01 | 7 | 0 | 84 | 2 | 01 | 8 |
| 2000-01-01 | 7 | 0 | 83 | 1 | 02 | 9 |
| 2000-01-01 | 7 | 0 | 85 | 2 | 02 | 7 |
| 2000-01-01 | 7 | 0 | 40 | 1 | 03 | 8 |
Le champ biss, s’il est à 1, indique les 29 février, qu’on ignorera pour InseeFine.
Table InseeFine
Ensuite, nous pourrons créer la table InseeFine en appelant la procédure CreateListeFine
| dt | dow | age | dep | deces | solde | cumul |
|---|---|---|---|---|---|---|
| 2000-01-01 | 7 | 65 | 04 | 2 | 547099 | 2 |
| 2000-01-01 | 7 | 65 | 29 | 16 | 547083 | 18 |
| 2000-01-02 | 1 | 65 | 23 | 5 | 547078 | 23 |
| 2000-01-02 | 1 | 65 | 83 | 21 | 547057 | 44 |
| 2000-01-03 | 2 | 65 | 02 | 6 | 547051 | 50 |
| 2000-01-03 | 2 | 65 | 52 | 4 | 547047 | 54 |
| 2000-01-04 | 3 | 65 | 2A | 2 | 547045 | 56 |
Il convient de noter que dans la liste InseeFine, toutes les personnes décédées à plus de 105 ans sont notées comme ayant 105 ans, pour rester cohérent avec la pyramide des âges dans laquelle les personnes de plus de 105 ans sont regroupées dans la tranche 105. Aussi, dans la liste fine, il n’y a pas de 29 février. Ils sont purement et simplement ignorés, on a donc seulement des années de 365 jours.
La table InseeFine tient compte, lors de sa création, des mouvements naturels, qui sont en fait la résultante des flux migratoires, mais pas que. Ca permet à l’Insee de remettre chaque année la pyramide des âges en adéquation avec la situation démographique au premier janvier. En pratique, comme nous connaissons le nombre de mouvements (en positif ou négatif) pour chaque âge, chaque année, nous allons, lors de l’élaboration de InseeFine, au premier jour de chaque mois, ajouter 1/12ème de cette valeur au solde courant. Les flux seront ainsi répartis de manière linéaire sur chaque mois pour rattraper la pyramide des âges à an+1.
Pyramide des âges
Pour construire la pyramide des âges, j’ai commencé par collationner, dans un fichier excel, les différentes données pour les années allant de 2000 à 2021.
Les données sont issues :
De 2000 à 2017, la source est le fichier fm_t6.xls aussi nommé irsocsd2018_t6_fm.xlsx
- https://www.insee.fr/fr/outil-interactif/2418118/xls/irsocsd2018_t6_fm.xlsx
- https://www.insee.fr/fr/statistiques/fichier/4503164/fm_t6.xlsx
Pour les années 2018 à 2021, les sources considérées sont les fichiers
- https://www.insee.fr/fr/statistiques/fichier/5007688/Pyramides-des-ages-2018.xlsx
- https://www.insee.fr/fr/statistiques/fichier/5007688/Pyramides-des-ages-2019.xlsx
- https://www.insee.fr/fr/statistiques/fichier/5007688/Pyramides-des-ages-2020.xlsx
- https://www.insee.fr/fr/statistiques/fichier/5007688/Pyramides-des-ages-2021.xlsx
| id | src | naiss | agerev | hommes | femmes | deces | mouv |
|---|---|---|---|---|---|---|---|
| 2121 | 2020 | 2019 | 0 | 344062 | 330998 | 1391 | 6243 |
| 2122 | 2020 | 2018 | 1 | 350477 | 334534 | 109 | 5022 |
| 2123 | 2020 | 2017 | 2 | 357183 | 343959 | 129 | 6748 |
| 2124 | 2020 | 2016 | 3 | 367875 | 352623 | 27 | 7684 |
| 2125 | 2020 | 2015 | 4 | 378954 | 362135 | 71 | 6630 |
| 2126 | 2020 | 2014 | 5 | 388704 | 376039 | 8 | 6192 |
Champ Mouv
Le Champ mouv résulte du calcul suivant :
Mouv=pop(an+1,age+1)-pop(an,age)-décès(an,age)
Cela correspond aux mouvements naturels sur l’année considérée à cet âge.
Ainsi on voit que 1.391 bambins de moins d’un an sont morts au cours de l’année 2020, et que les mouvements naturels pour cette tranche d’âge s’établissent à 6.243. L’intégration de ces mouvements dans le calcul de InseeFine trouve sa raison dans le fait qu’une fois arrivés sur le territoire, ces gens mourront grosso modo dans les mêmes proportions que les Français au même âge. De facto cela « minimise » la mortalité dans la tranche d’âge considérée, mais cela correspond à une réalité démographique.
Validation du modèle
Un petit dessin vaut mieux qu’un long discours, dit-on, ainsi un graphique matérialisant les erreurs entre les courbes issues des séries longues de l’Insee et les miennes nous permettra de voir en un clin d’oeil que les courbes sont bien les mêmes. Pour cela, je me suis basé sur les listes Insee idBank 000436394 – Démographie – Nombre de décès – France métropolitaine.
Ensuite je compare avec mes propres données issues de la table InseeShort, une fois en ne filtrant pas les ErCode9 (lieu de décès inconnu cité plus haut), et la même série en excluant ces ErCode9.
Voici ce que donne le graphique des erreurs (qui devraient idéalement se rapprocher de zéro) :
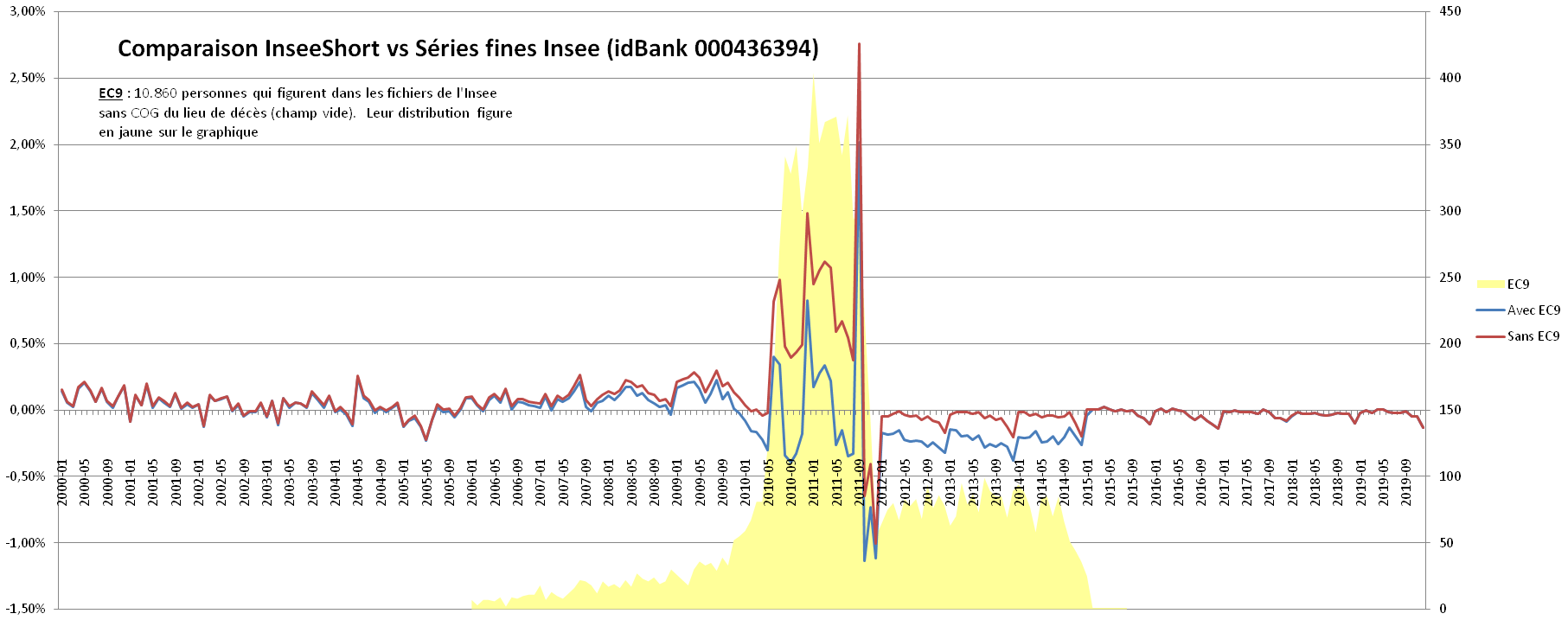
En jaune, la répartition de ces curieux décès sans COG lieu de décès. On voit que la courbe rouge, celle qui filtre les fameuses fiches sans lieu de décès, se rapproche nettement plus de zéro, notamment pour ce qui concerne la période allant de janvier 2012 à décembre 2019.
On voit aussi qu’il y a des pics vers le bas, récurrents chaque année en janvier, probablement des ajustements manuels réalisés à l’Insee.
- Sur l’ensemble de la courbe, l’erreur moyenne est de 0,13% soit 13 dix-millièmes
- Sur la période 2012 – 2019, l’erreur moyenne n’est que de 0,04% soit 4 dix-millièmes
On atteint donc à partir de 2012 une précision excellente, rendant les séries parfaitement adaptées à des analyses fines.
Les anomalies observables sur le graphique interviennent en : déc2010, sept2011, oct2011 et déc2011, et ce sont probablement les séries fines qui ne sont pas correctes, vu que le modèle colle presque parfaitement pour tous les autres points, et puis pour les décès, ben on a les noms, alors soit on en a trop (et ils ont oublié de les intégrer), soit il en manque dans les listes de remontées, mais alors comment ont-il bien pu confectionner leur liste longue?
On voit, notamment sur la période allant de mai 2010 à août 2011, on a probablement chèvrechouté avec des fameuses fiches aujourd’hui sans lieu de décès. Si l’on prenait sur cette période une moyenne de la courbe rouge et de la bleue, on aurait une courbe qui se rapprocherait plus de zéro, à l’exception des anomalies mentionnées plus haut.
Vous pouvez télécharger ici le document excel sur lequel je me suis basé pour ces validations.
Mise à disposition au téléchargement
Le but du projet, c’est de permettre à chacun de reconstruire/maintenir lui-même l’ensemble des données affinées. Pourquoi les reconstruire? Tout simplement parce que les fichiers sont énormes, mais aussi pour vous permettre de travailler sur des données dont vous connaissez l’origine (l’Insee), et vous donner le moyen de vérifier précisément à chaque étape le traitement qui est effectué. Sans fiabilité, reproductibilité et transparence, l’initiative ne vaut rien.
En premier lieu, vous devrez récupérer auprès de l’Insee l’ensemble des fichiers de remontées entre 1970 et février 2021, et les sauver tous dans le même sous-répertoire. Attention, le fichier 1996 est en ANSI, il faut le convertir en UTF8 avec NotePad++ par ex. sinon ça crashera à l’import. Cela devrait faire 51 fichiers annuels « deces-AAAA.csv » plus deux fichiers, l’un pour janvier 2021 (Deces_2021_M01.csv) et l’autre pour février 2021 (Deces_2021_M02.csv).
Les bases de données ont été créées en MySql, vous devrez donc commencer par en télécharger une version, ainsi que le WorkBench, si vous travaillez sous Windows. Moi je me suis contenté d’une vieille version 5.6.16, et cela devrait aller aussi, bien sûr, avec une version plus récente.
Ensuite, dans le WorkBench, vous devrez modifier le timeout, soit le temps maximal d’exécution d’une requête. Par défaut c’est à 600 secondes, c’est trop peu. Pour cela allez dans EDIT / PREFERENCES, puis augmentez cette valeur, moi j’ai mis 18.000 même si je sais que c’est trop.
Ensuite vous devrez créer une base de données, que vous appellerez « mortalite » (sans accent).
Ensuite, vous devrez récupérer ici le backup du squelette de la base, via l’option data import/restore (en un fichier), en indiquant le fichier que vous aurez préalablement décompressé.
Ensuite, vous devrez récupérer ici les différents fichiers relatifs au projet. Dans le répertoire « Queries MySql », vous trouverez le fichier « All_in_one.sql », ouvrez-le. Vous allez devoir remplacer le chemin pour les fichiers d’import, soit remplacer « e:/Documents/CovidInsee/Fichiers sources/Insee/ » par le nom du répertoire dans lequel vous avez regroupé tous les fichiers csv de l’Insee.
Lancez ensuite le script, vérifiez qu’il va bien importer les csv (ça prend 4 minutes chez moi), puis qu’il va bien commencer à exécuter les requêtes pour marquer les fiches en erreur ou en double.
Si à ce stade ça passe, vous n’avez plus qu’à attendre (environ 2h40 chez moi), que tout soit fini.
![]()







Bravo! Belle démonstration.